Appearance
Call Capacity and Load Testing CURRI API
The default OVA is sized with capacity for most installations.
Default Capacity of Vmware Appliance
The OVA Appliance is generally sized for about 300-400 concurrent calls insepctions per second under 3ms round trip time, constant load (95th percentile) over ethernet. This will vary depending on your host CPU hardware, but is a good baseline for many installations.
Below is an actual load test sample, on version 0.8.1, in March 2024.
Host Environment
- Lenovo Micro PC I9-10500T
- Vmware 7.0
- Guest VM - Default Call Telemetry OVA - 2vCPU, 6GB RAM.
Test Examples
0.8.1 - Default OVA Appliance 2 vCPU / 4GB Ram
- Client 2019 Macbook Pro over ethernet
- 200 CURRI API Calls per second
- P95 Latency: 4-5ms
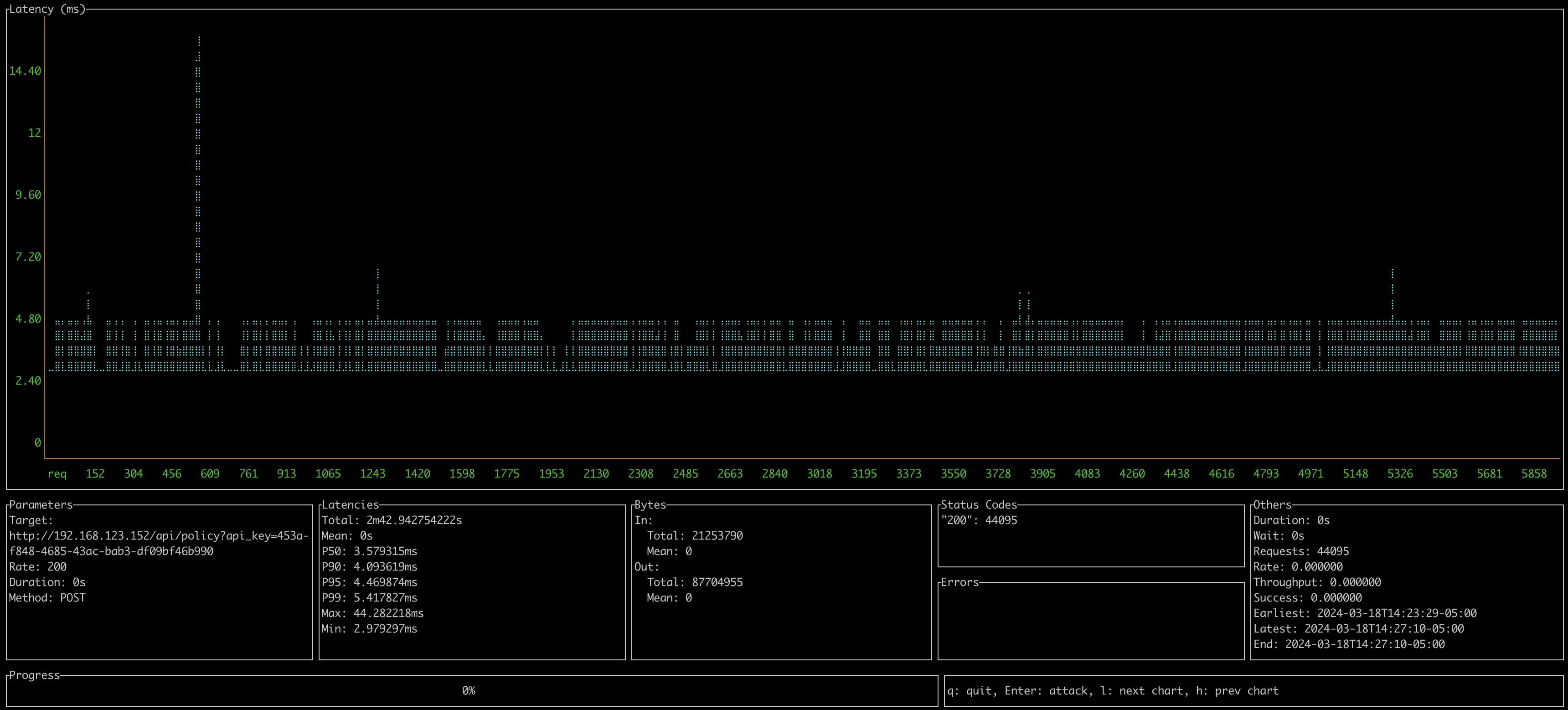
0.8.4 - Default OVA Appliance 2 vCPU / 6GB Ram
- Client 2019 Macbook Pro over wireless
- 200 CURRI API Calls per second
- P95 Latency: 11-12ms
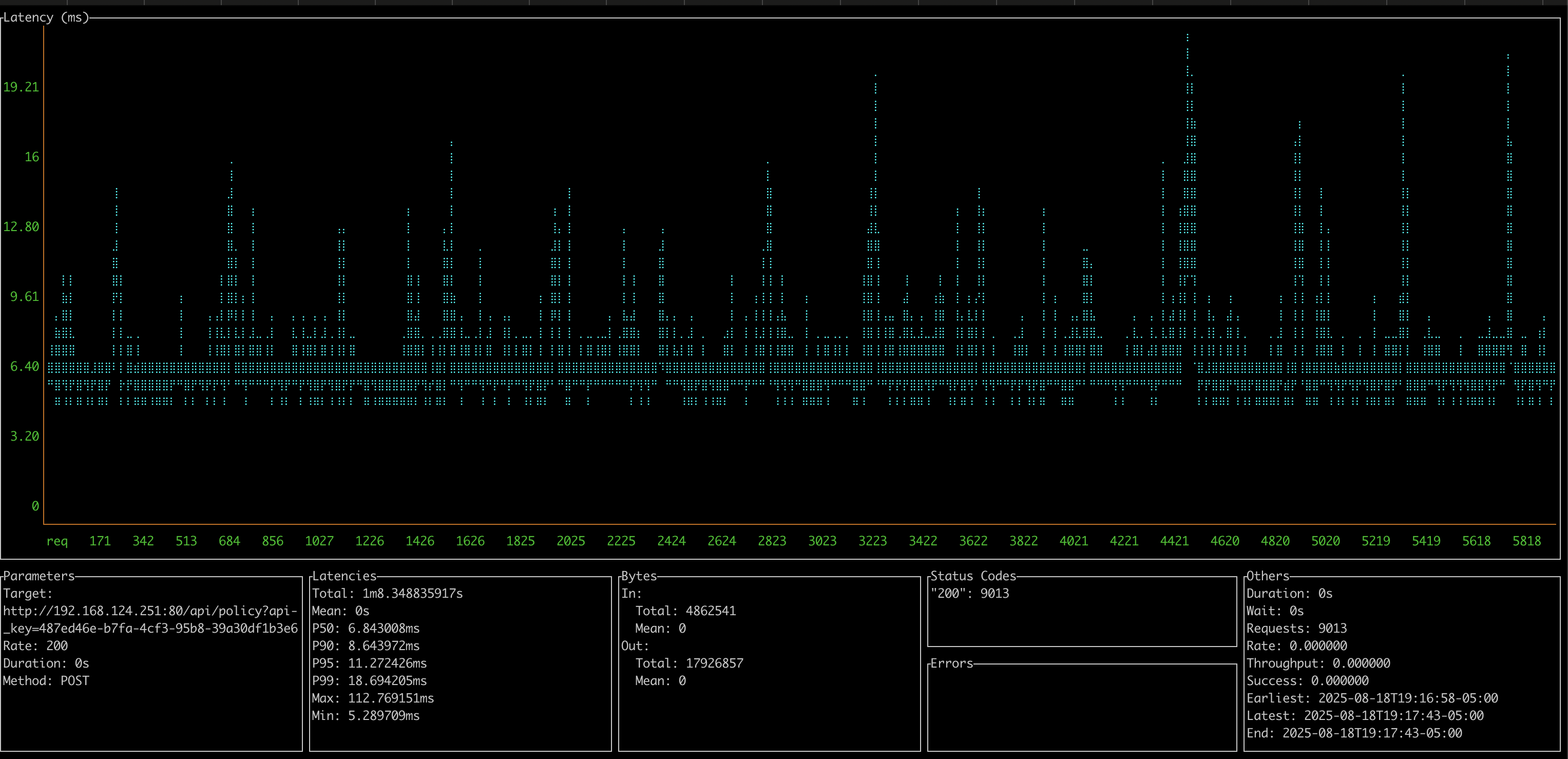
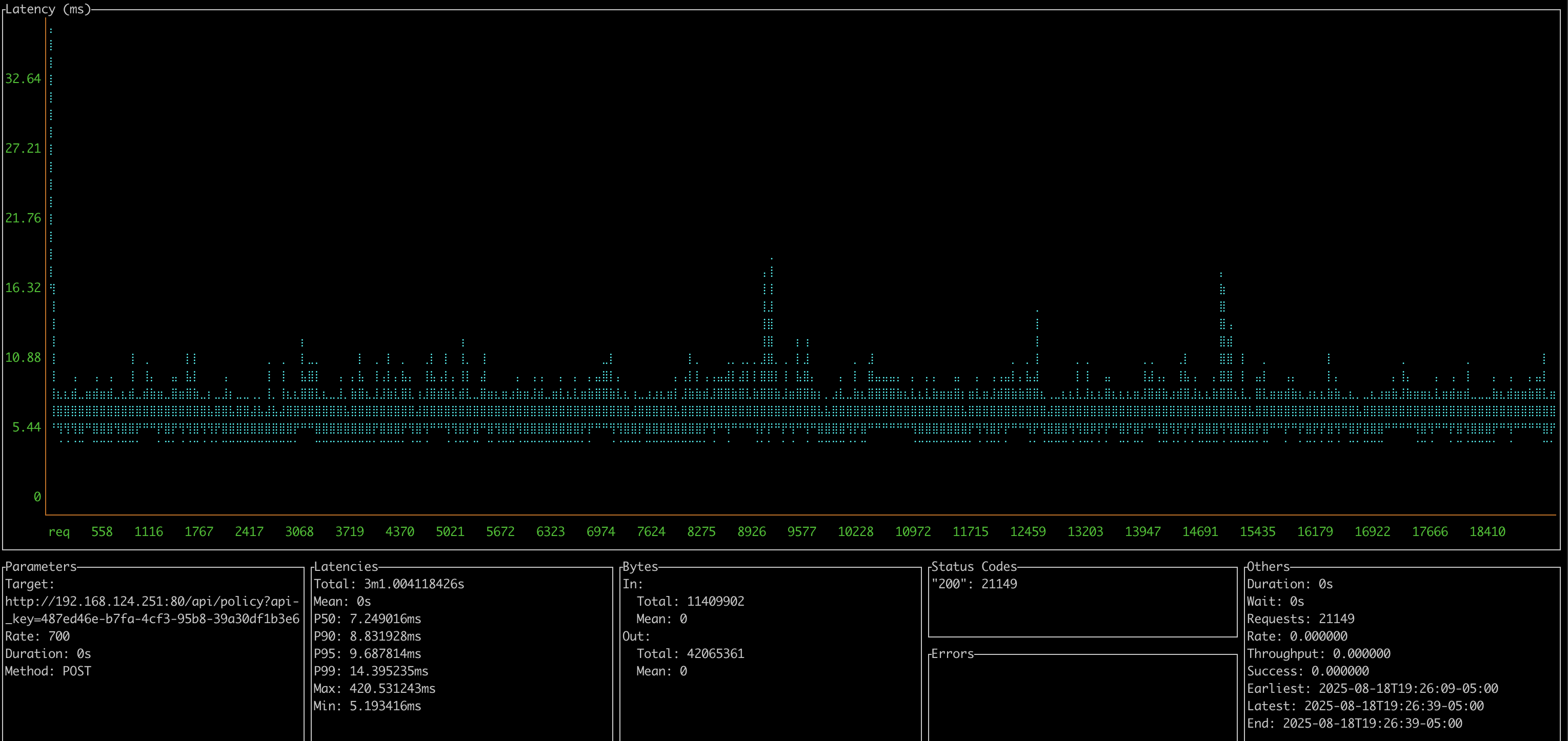
0.8.4 - OVA Appliance with 8 vCPU / 6GB Ram
- Client 2019 Macbook Pro over wireless
- 700 CURRI API Calls per second
- P95 Latency: 9-10ms
- Server at about 60% CPU load
TIP
You can scale the OVA by increasing vCPU, each vCPU increases about 100 calls per second. Lab Tested above at 700 call inspections per second. HA Cluster load balancing acheives even higher numbers if needed.
Load Testing your own Appliance
Below is a guide for load-testing the appliance and your hardware. Load Testing Guide
What happens if the appliance becomes overloaded?
If overloaded, the request from Cisco Callmanager may timeout. CUCM will timeout, this is configurable in Service Parameters. Calls will continue according to the ECC profile setting default - which defaults to allow calls. Most users will choose to allow the call if the API times out.
If you want to increase the capacity, just add more vCPU. The multi-core architecture supports about 100 new call real-time policy inspections per vCPU per second.
Failover Concerns
The Enterprise HA Kubernetes option provides failover for the appliation and the PostgreSQL database. This is a 3 node cluster, and can handle a node failure. SQL is replicated across nodes. The extra nodes also increase overall capacity by load balancing.